The aim is to set up Graylog easily to be able to play around with it for a little while and see if you want to explore further and dive deep into more details. To reach that goal I have prepared todo app with quite smooth process of configuration for the whole solution without many unnecessary details. So it’s kinda MVP which can be used to create something more sophisticated. We will go through some basic information which might be helpful to understand how it all works together because there are several essential components that work together.
Why you may need Graylog
Graylog allows you to have a central place where your logs are stored. As stated in GitHub repository, it is “free and open log management platform” written in Java. It allows you to gather logs from a lot of different sources: servers, firewalls or applications built on your own like presented here later. We can simplify it to being some kind of abstraction layer on top of other tools making some work for you making and hiding part of complexity. In comparison to other similar solution like ELK it seems easier to get started with.
Architecture
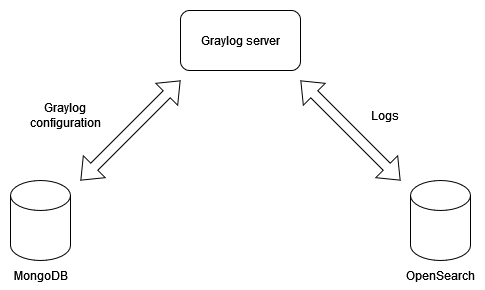
It consists of 3 main parts: database to store Graylog configuration, Graylog itself which is API and UI and a data node.
Let’s start with a key component of whole solution which is a data node. Actually, it is a full text search engine. It is the place where logs are stored and what allows to look across stored logs that can be searched efficiently. I guess your first thought about search engine was the ElasticSearch but because of dispute between it and AWS we can choose between ES and OpenSearch where the latter is fork of ES. The OpenSearch is recommended from now on because Elastic will not be supported in newer versions.
Next we have Graylog API and UI which allows to configure everything. It joins all these pieces together to make it easier for you. What is important to point out is the fact that UI uses the same endpoints which are available for you. In your browser’s developer tool you can spy on requests used by UI when API documentation isn’t clear enough. These endpoints may help you e.g. makes some automation scripts to configure Graylog without you even touching UI.
The last part is the MongoDb which is a storage for configuration.
More about architecture and how to scale whole solution you can find in this YT video.
Building blocks
Inputs
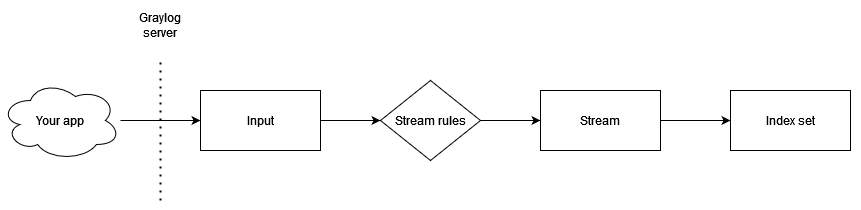
Depending on your requirements there are several options for how data gets into Graylog. You can choose between push and pull model. If your logs are streamed using Kafka, Graylog is able to subscribe it. If your logs are only available in log files, you can use FileBeats to collect them. A simple option is when your application sends logs by UDP or TCP protocol directly to Graylog, so that’s the case you will see later in code. For more options visit dedicated section in documentation.
Interesting part might be GELF acronym which appears next to inputs. It is Graylog’s own logs format that solves some issues of classic plain syslog:
- No length limit to 1024 bytes
- Datatypes support, numbers and string are distinguishable
- Compression
- Chunking, if message is too big, slice it into multiple chunks
Indices
This is where some knowledge about OpenSearch concepts and good practices is helpful. Even though Graylog is abstraction layer over ES you still need to know how to set indices parameters to do it properly for your usecase, especially to met non-functional requirements if you want to scale it properly. Indices maps transparently on the same term used in the search engine. Indices can be grouped in index sets because of aliases usage. Every index and index sets allows for setting their rotation and retention strategy what may differ from one usecase to another. Thanks to aliases your logs are routed to the current write-active index. There’s a background process that automatically manages index rotation. When criteria are met it switch atomically to a new index without you noticing. You can additionally decide what happens next, if rotated index should be deleted, archived or closed.
Streams
Streams are where you can decide about criteria which logs have to met to be saved.
By default, all logs are directed to Default Stream.
Of course, you can create your own stream. When you create it you choose in which index these logs
will be saved and if logs will be saved exclusively in your newly created stream or also duplicated in default one.
When it is created rules can be defined what allows for filtering on any field in your
logs e.g. server name from which they were sent.
Later stream are used to fetch data, filter them and even aggregate to prepare visual diagrams.
Concrete usecase
To present you how Graylog can be used I’ve prepared a solution based on .NET app. To deliver logs from app to Graylog I’ve used UDP protocol. It’s simple todo app without any sophisticated domain logic or complex technical solutions. For logging a Serilog library is used with structural logs approach and Graylog as a sink. It should be quite easy to switch to Graylog usage in your case if you are using this package.
Graylog’s infrastructure
First we need to have Graylog up and running. I’ve prepared docker-compose’s file in GitHub repo with all required services for Graylog setup. I will explain shortly what happens there. We have all 3 required services mentioned in one of the section above. All of them uses network simple_todo created by other docker-compose file with PostgreSQL which is used by app to save data. All containers have volumes bind to local disc and all data are saved in dedicated docker catalog. Most interesting for us in context of integration with Graylog is fact that port on number 12201 (UDP) is made available to the public so can be used for input configuration. Rest of sections you are not familiar with are explained by comments added next to them.
Now it is time to run prepared file:
docker-compose up -d docker-compose.graylog.yml
To be sure that all works properly wait up to the moment an url localhost:9000 will start serving Graylog UI. Then we have two alternatives:
- Using UI to configure Graylog.
- Use bash script which do it our behalf.
We move on with easier option. To do it, run graylog_setup.sh script.
cd ./infrastructure ./graylog_setup.shIt uses the same HTTP API what Graylog’s frontend. There are few steps:
- Create index.
- Create UDP input accessible by port 12201.
- Creates stream with rule filtering only logs containing ApplicationName field with value SimpleTodo.
- Start stream to allows logs flow through it.
Now you can log in and click through Graylog app to see how it all is configured. When this part is ready we can move on to the next step where we will start todo app.
Todo app
The most important part of this application in context of this article is of course logging. Structured logs approach was applied with Serilog. There is several nuget packages required to set up logging as expected:
- Serilog and Serilog.AspNetCore - core packages allowing to use basic logging functionalities.
- Serilog.Settings.Configuration - if you prefer to have configuration in appSetting.json this package allows it.
- Serilog.Enrichers.Thread - allows for thread number attaching to every logged message.
- Serilog.Sinks.Graylog - allows direct logs right to Graylog.
Every log contains property with application name what can be used then in Graylog’s stream to filter only logs from this app in case more than one logs source. Enricher have to be defined, without it this additional property is not added.
{
"Properties": {
"ApplicationName": "SimpleTodo"
},
"Enrich": [
"FromConfiguration"
]
}
In addition to the nuget package installation, we must also specify where the Graylog is and how to send logs, in this case UDP on defined port and IP.
{
"WriteTo": [
{
"Name": "Graylog",
"Args": {
"hostnameOrAddress": "127.0.0.1",
"port": "12201",
"transportType": "Udp"
}
}
]
}
Now it’s time to run Todo application.
cd src/SimpleTodo/
dotnet run
When app is ready to use, let’s produce some logs. There is api.http file where example API endpoint execution is prepared so adding new todo can be done. Alternatively swagger UI can be used for that.
Then open Graylog on localhost:9000.
Open Stream page and select this named simple_todo-core. If any log was produced it should appear there if valid time range selected.
Summary
We’ve covered the basics of Graylog here. Graylog offers a lot more. Some things you might be interested in are alerts, content packs, pipelines and more advanced dashboards. In free version basic access management is included. It’s worth exploring what else Graylog can offer. You can add extra logs even to presented application in this article and test what you can with data from logs especially in context of adding widgets in dashboards.